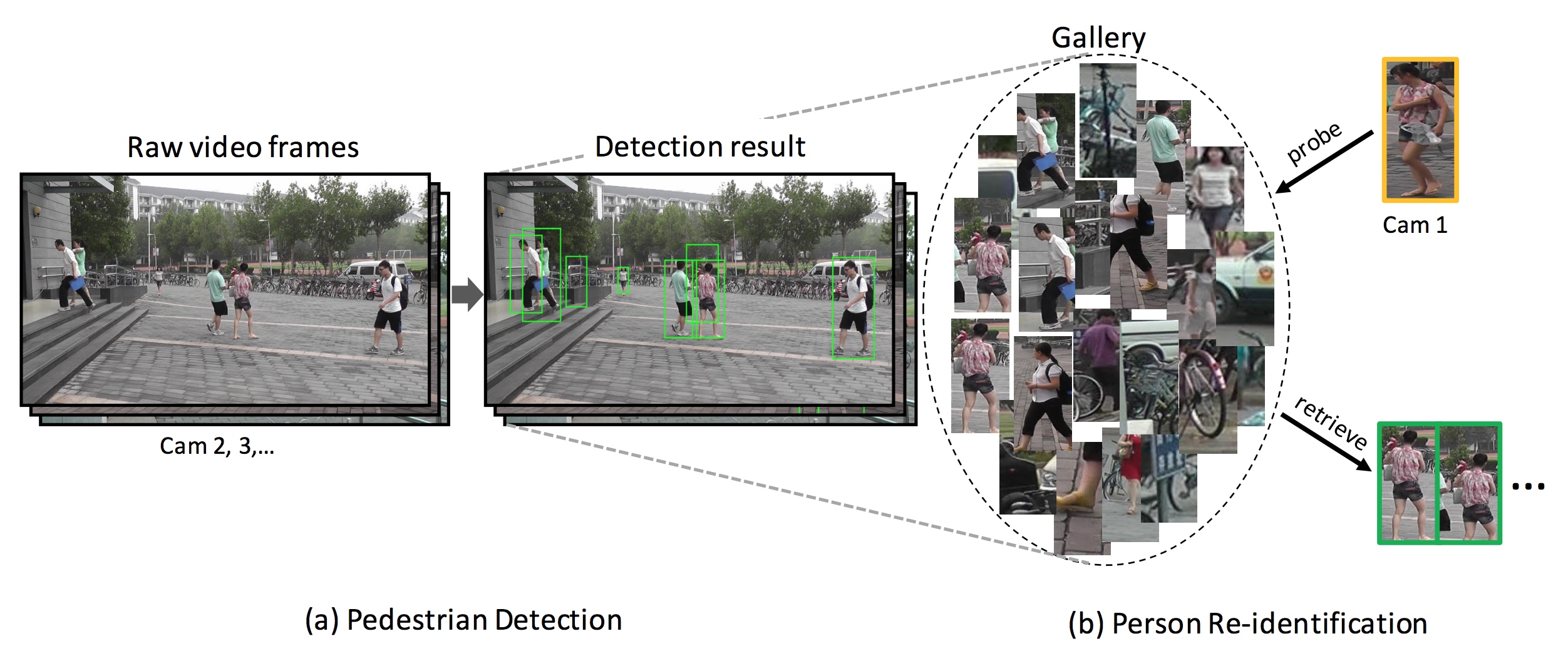
目標
難度
- 目標遮擋(Occlusion)導致部分特徵丟失
- 不同的 View,Illumination 導致同一目標的特徵差異
- 不同目標衣服顏色近似、特徵近似導致區分度下降
解決方案
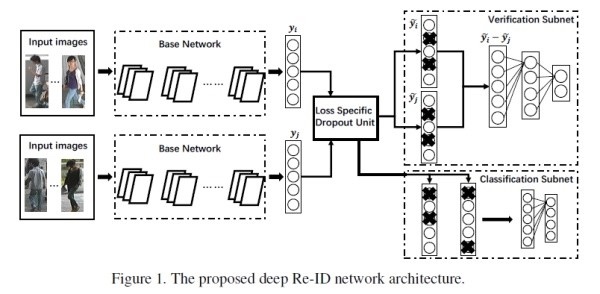
1. Representation learning + ReID
看做分類(Classification/Identification)問題或者驗證(Verification)問題:
(1) 分類問題是指利用行人的ID或者屬性等作為訓練標籤來訓練模型;
(2) 驗證問題是指輸入一對(兩張)行人圖片,讓網絡來學習這兩張圖片是否屬於同一個行人。
Classification/Identification loss和verification loss
額外改進方向[2]是在加上許多行人的label,像是性別、頭髮以及服裝等等。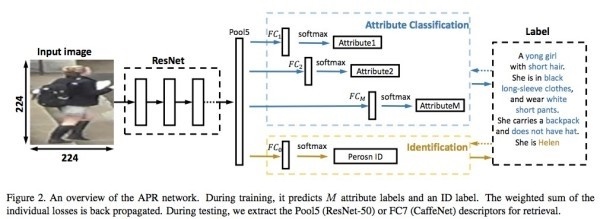
2. Metric learning + ReID
常用於圖像檢索的方法,通過網絡學習出兩張圖片的相似度。
(Contrastive loss)[5]、三元組損失(Triplet loss)、 四元組損失(Quadruplet loss)、難樣本採樣三元組損失(Triplet hard loss with batch hard mining, TriHard loss)、邊界挖掘損失(Margin sample mining loss, MSML
Contrastive loss 基本上就是Siamese CNN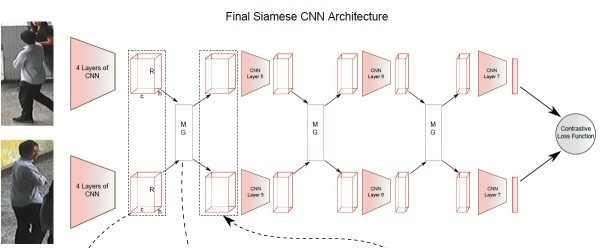
訓練時是三個正樣本一個副樣本,test時未知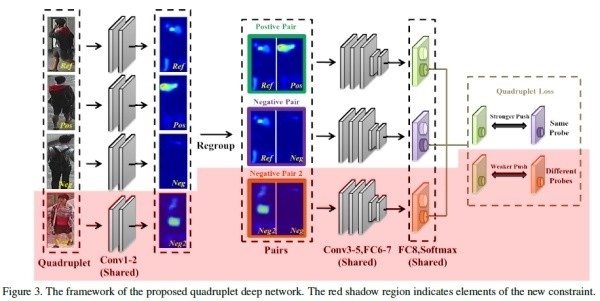
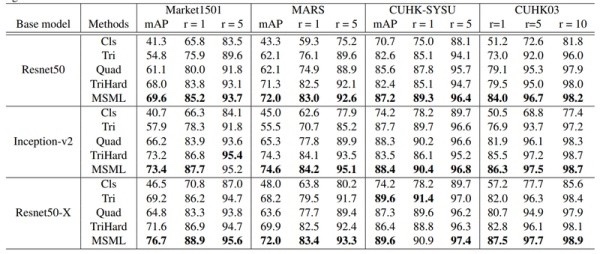
3. Local Feature + ReID
論文[3]用local feature而不用global feature,切割好以後送到LSTM去學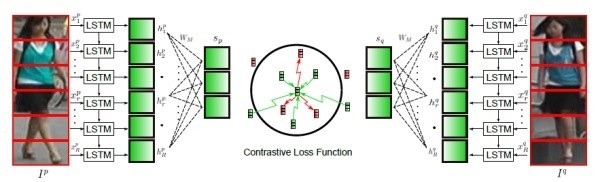
但論文[3]會有對齊問題,所以論文[4]用pose跟skeleton來做姿勢預測,再通過仿射變換對齊

論文[5]直接拿關節點切出ROI,14個人體關節點,得到7個ROI區域,(頭、上身、下身和四肢)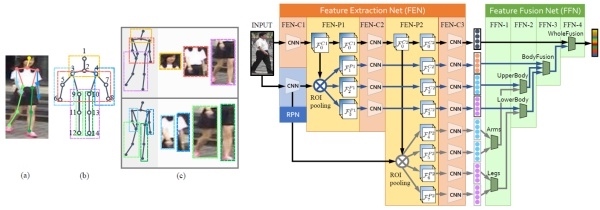
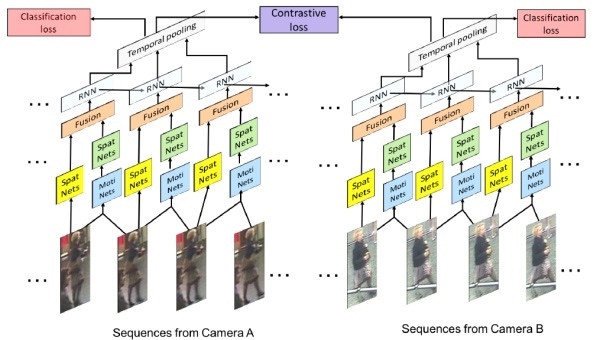
4. Video Sequence + ReID
這方向不熟 貼兩張圖參考參考而已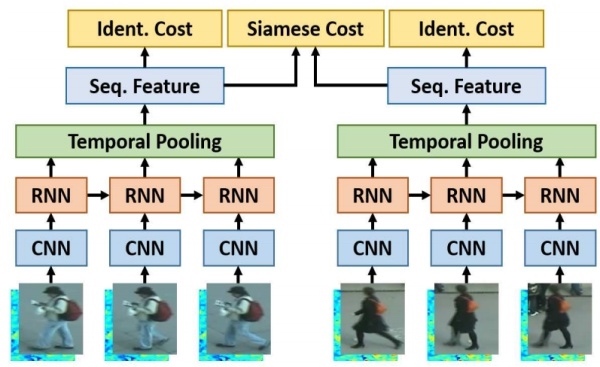
5. GAN + ReID
ReID數據集目前最大的也只有幾千個ID,跟萬張圖片而已,CNN based還容易overfitting
GAN主要是用在遷移學習跟基於條件的生成
第一篇就是ICCV2017的論文[5]以及後來同作者改進的論文[6],是可以避免overfitting但生成效果就很慘
為了處理不同數據集,甚至是不同camera所造成bias的問題,論文[7]是利用cycleGAN based的設計,利用遷移學習來處理兩個數同數據集的問題,先切割分前景跟背景,在轉換過去。
D有兩個loss(還是有兩個D不確定,paper內沒架構圖)一個是前景的絕對誤差loss,一個是正常的判別器loss。判別器loss是用來判斷生成的圖屬於哪個domain,前景的loss是為了保證行人前景儘可能逼真不變。mask用PSPnet來找的。

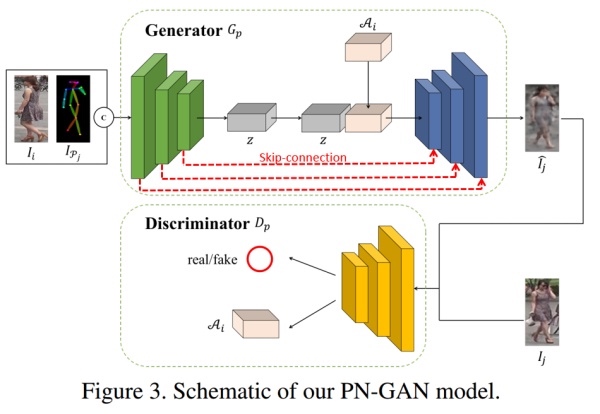
Pose Normalization[8]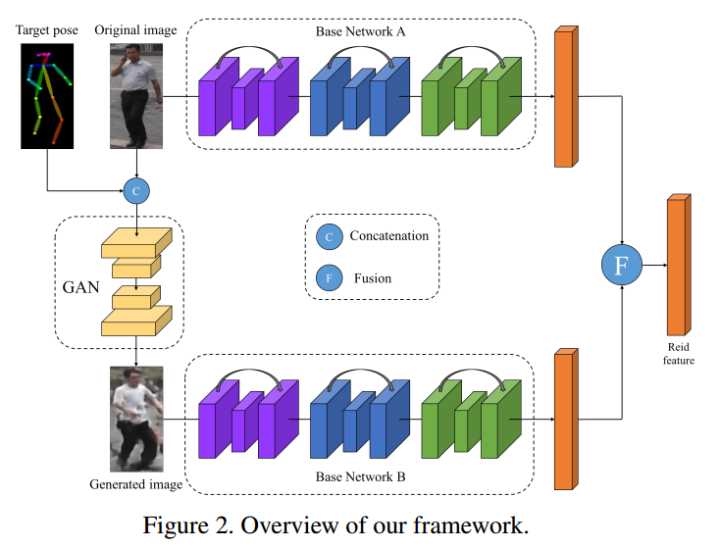

資料種類
- Video-based
- Image-based
- Long-term activity
- Individual action
資料庫
程式碼
简单行人重识别代码到88%准确率
https://github.com/layumi/Person_reID_baseline_pytorch
ICCV 2017
- Cross-view Asymmetric Metric Learning for Unsupervised Re-id
- Deeply-Learned Part-Aligned Representations for Person Re-Identification
- In Defense of the Triplet Loss for Person Re-Identification
- Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
- SVDNet for Pedestrian Retrieval
- Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
Paper List
- Point to Set Similarity Based Deep Feature Learning for Person Re-Identification
- Fast Person Re-Identification via Cross-Camera Semantic Binary Transformation
- See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-Based Person Re-Identification
- Learning Deep Context-Aware Features Over Body and Latent Parts for Person Re-Identification
- Consistent-Aware Deep Learning for Person Re-Identification in a Camera Network
- Re-Ranking Person Re-Identification With k-Reciprocal Encoding
- Multiple People Tracking by Lifted Multicut and Person Re-Identification
[1] Mengyue Geng, Yaowei Wang, Tao Xiang, Yonghong Tian. Deep transfer learning for person reidentification[J]. arXiv preprint arXiv:1611.05244, 2016.
[2] Yutian Lin, Liang Zheng, Zhedong Zheng, YuWu, Yi Yang. Improving person re-identification by attribute and identity learning[J]. arXiv preprint arXiv:1703.07220, 2017.
[3] Rahul Rama Varior, Bing Shuai, Jiwen Lu, Dong Xu, Gang Wang. A siamese long short-term memory architecture for human re-identification[C]//European Conference on Computer Vision. Springer, 2016:135–153.
[4]Liang Zheng, Yujia Huang, Huchuan Lu, Yi Yang. Pose invariant embedding for deep person reidentification[J]. arXiv preprint arXiv:1701.07732, 2017.
[5] Haiyu Zhao, Maoqing Tian, Shuyang Sun, Jing Shao, Junjie Yan, Shuai Yi, Xiaogang Wang, Xiaoou Tang. Spindle net: Person re-identification with human body region guided feature decomposition and fusion[C]. CVPR, 2017.
[6] Zhong Z, Zheng L, Zheng Z, et al. Camera Style Adaptation for Person Re-identification[J]. arXiv preprint arXiv:1711.10295, 2017.
[7] Wei L, Zhang S, Gao W, et al. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification[J]. arXiv preprint arXiv:1711.08565, 2017.
[8] Qian X, Fu Y, Wang W, et al. Pose-Normalized Image Generation for Person Re-identification[J]. arXiv preprint arXiv:1712.02225, 2017.