Recap
Quote:
其實很討厭這作者的paper
效果都很好, 但是每次都是用matlab, 而且PSPNet作者還說training code因為公司問題不能發布, 傻眼
https://www.zhihu.com/question/53356671
Paper
https://arxiv.org/pdf/1704.08545.pdf
Code
https://github.com/hszhao/ICNet
https://github.com/aitorzip/Keras-ICNet
https://github.com/hellochick/ICNet-tensorflow
Key Difference
之前的那些方法,如FCN、SegNet、UNet、RefineNet等,用高解析度圖片當input以後,強調Single scale或是Multi Scale在不同層之間的特徵融合,所有的Data需要在整個網絡中運行,因為高解析度的輸入而導致了昂貴的計算費用.而本文的方法,使用低解析度圖片作為主要輸入,採用高解析度圖片進行refine,保留細節的同時減少了開銷.
Abstract
|
|
ICNet是一個基於PSPNet的real-time semantic segmentation network,論文內對PSPNet做深入的分析,並且找出影響inference speed*的缺點。並且用搭配multi-resolution cascade combination。
*註:inference speed是單指DeConv的階段。
Introduction
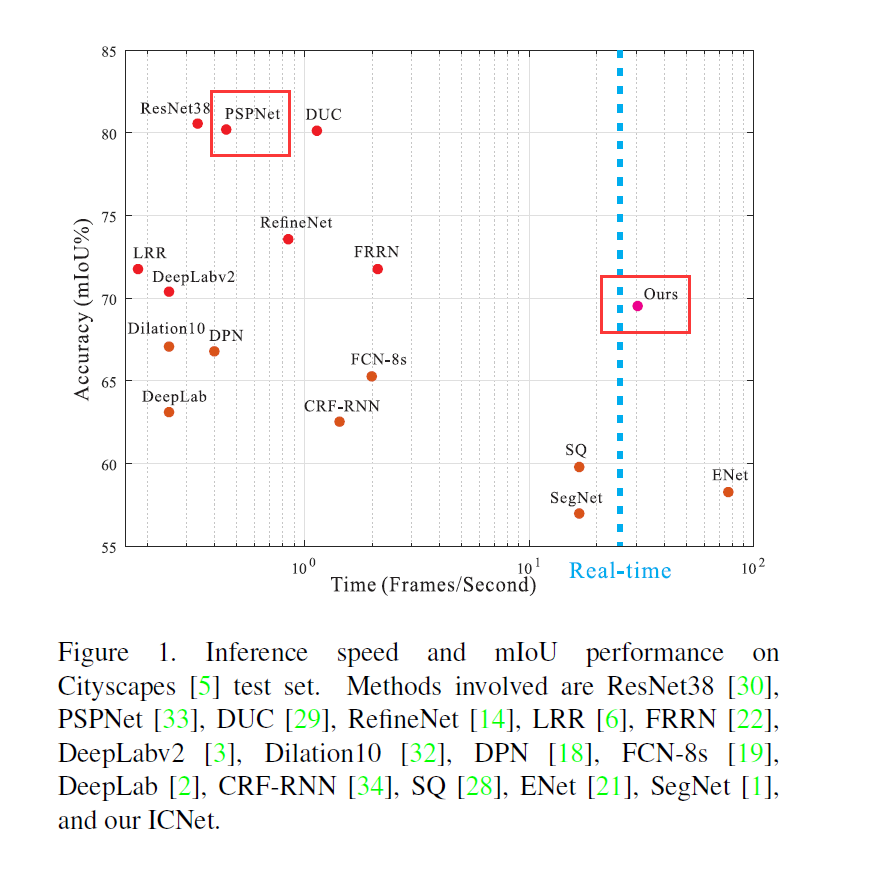
在論文發表的時刻(2017 March), CityScapes上所有的Model表現基本上分成兩種類型, 一種是擁有高精準度但速度不行, 另一種是速度快但精准度不行。此論文在PSPNet的基礎上來增進速度,並找一個速度跟精準度的平衡點。
論文貢獻:
- 可以在1024x2048的解析度下保持30 fps的計算速度(Tensorflow版本實測可行, 但要去掉preproccess部分)
- 相對PSPNet來說, 可疑提高5倍速度並可以減少五倍RAM消耗
- 低解析的速度+高解析的細節做cascade的整合
Speed Analysis
從PSPNet做解析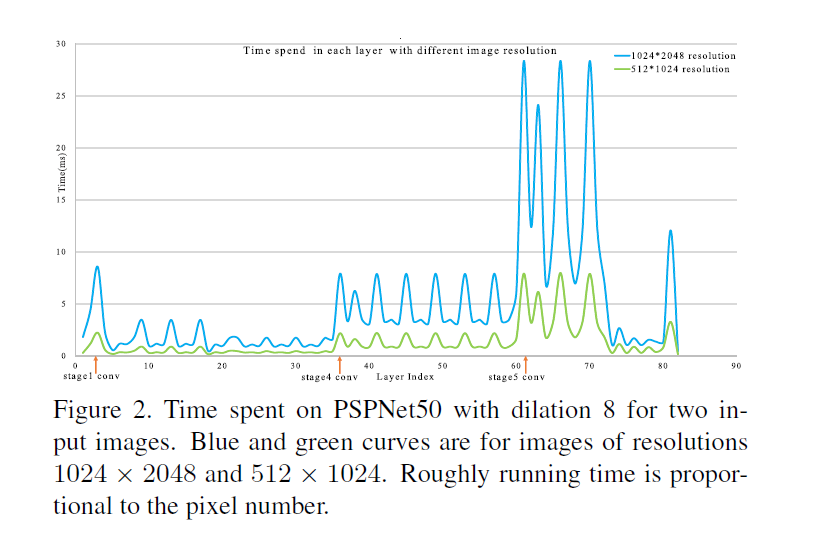
藍色是1024x2048, 綠色是512x1024 (1/4大小)
從上圖可知
- 圖越大速度越慢
- 網路寬度越大速度越慢
- Kernel越多速度越慢, 以圖中例子來說stage4跟stage5在解析同樣的input時, inference speed差距十分驚人, 因為這部分的kernel number差距了一倍。
Intuitive Speedup
加速方法 1: 輸入向下採樣(Downsampling Input)
在resolution只有原本的0.5跟0.25的狀況下雖然速度變快但精准度如上圖所示可以看出效果很差。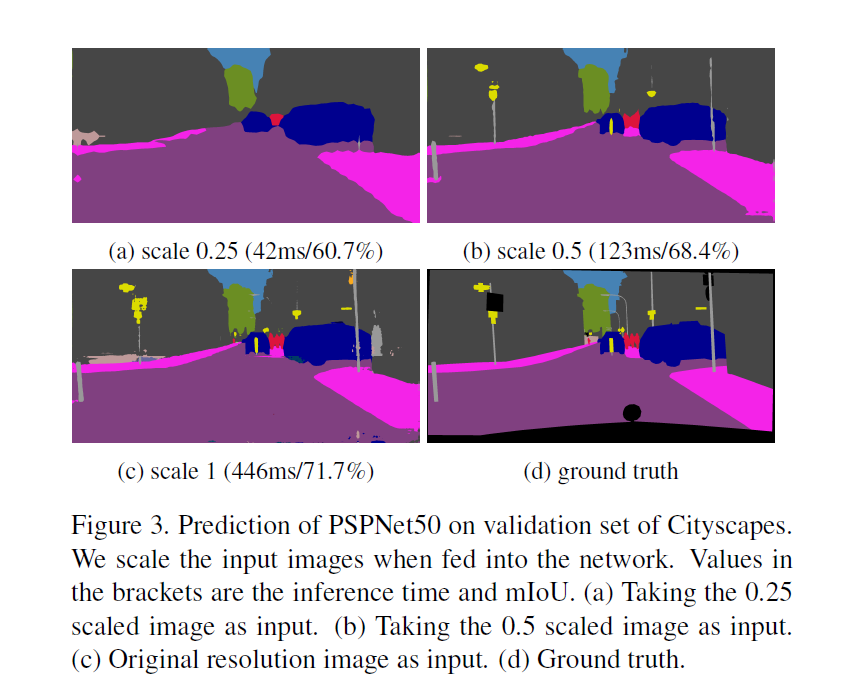
加速方法 2 : 利用較小的feature map來做inference(Downsampling Feature)
FCN Downsampling到32倍, Deep Lab到 8倍, 而下方是用作者之前的PSPNet50, 縮小到了1:8, 1:16, 1:32整理的Table, 但可以看到最快的速度也只有132ms, 不太能符合real-time的標準。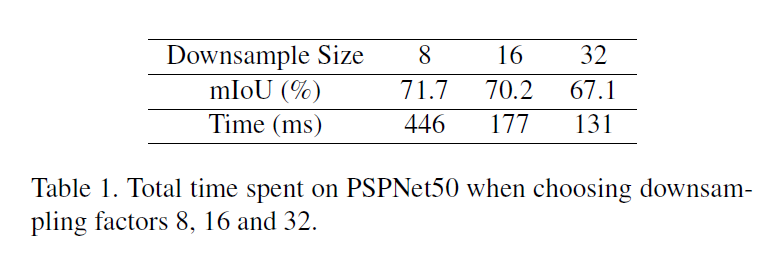
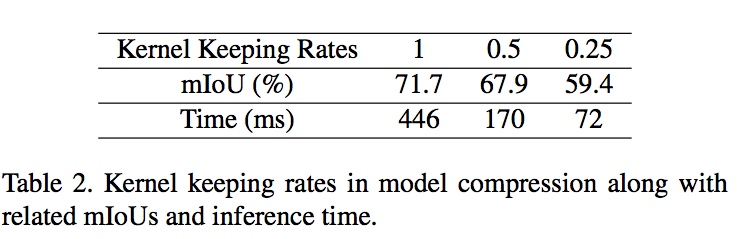
加速方法 3 : 減少模型複雜度(Model Compression)
採用了其他篇paper(Pruning filters for efficient convnets),作法就是減少Filter數量, 但一樣差強人意
FCN:Fully Convolutional Networks for Fully Convolutional Networks
這裡額外多講一下FCN,算是CNN做semantic segmentation的始祖,本質上的區別大概就是…FCN是沒有全連結層的CNN,好處是可以接受任意大小輸入。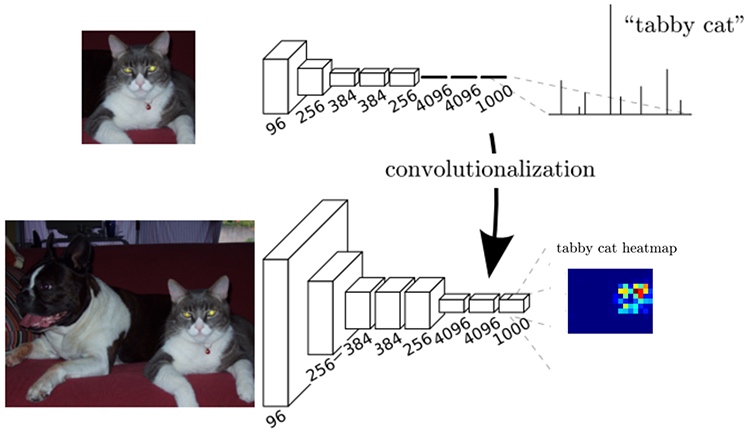
CNN要如何轉FCN? 以此篇paper為例,input是一個224x224x3的圖,經過一系列Conv跟Downsampling之後是7x7x512。
AlexNet使用了兩個4096的全連接層,最後一個有1000個神經元的全連接層用於計算分類評分。我們可以將這3個全連接層轉化為Convolution層。
任一全連結層轉化為Conv的方式以以下為例:
例如 K=4096 的全連接層,輸入是7x7x512,這個全連接層可以被等效地看做一個F=7,Padding=0,Stride=1,Filter Number=4096 的Conv層。換句話說,就是將Filter Size設置的和Input Data Size一致了。輸出將變成 1x1x4096,這個結果就和使用初始的那個全連接層一樣了。
針對第一個連接區域是[7x7x512]的全連接層,令其Filter Size為F=7(Filter Size為7x7),這樣輸出為[1x1x4096]。
針對第二個全連接層,令其Filter Size為F=1(Filter Size為1x1),這樣輸出為[1x1x4096]。
對最後一個全連接層也做類似的,令其F=1(Filter Size為1x1),最終輸出為[1x1x1000]
Step 1:
下圖是是原始CNN結構,CNN中輸入的圖像大小是統一固定resize成227x227大小的圖像,第一層pooling後為55x55,第二層pooling後為27x27,第五層pooling後的圖像大小為13*13。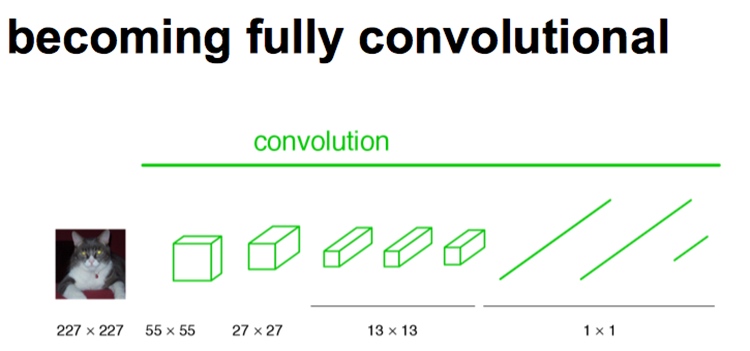
Step 2:
FCN輸入的圖像是假設是H*W,第一層pooling後變為原圖大小的1/4,第二層變為的1/8,第五層變為1/ 16,第八層變為1/32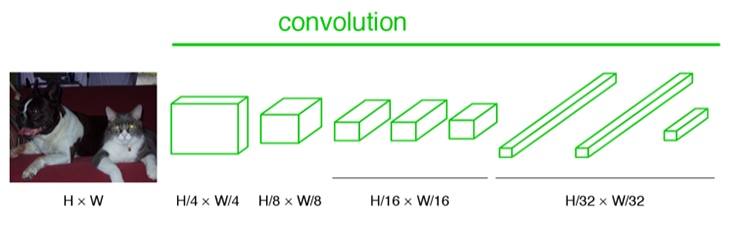
Step 3:
Convolution本質上就是DownSampling(下採樣)。經過多次Convolution和pooling以後,得到的圖像越來越小,解析度越來越低。其中圖像到H/32∗W/32 的時候圖片是最小的一層時,所產生圖叫做heatmap,heatmap就是我們最重要的高維特徵圖,得到高維特徵的heatmap之後就是最重要的一步也是最後的一步,就是對此heatmap進行UpSampling(Deconvolution),把圖像進行放大到原圖像的大小。
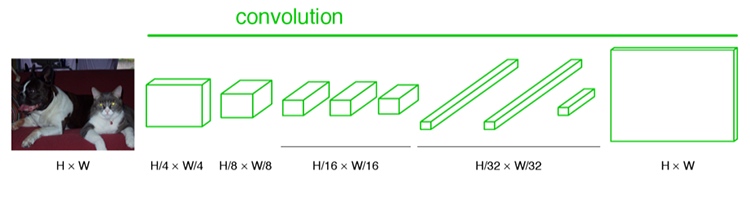
Step 4:
最後的輸出是1000張heatmap經過UpSampling變為原圖大小的圖片。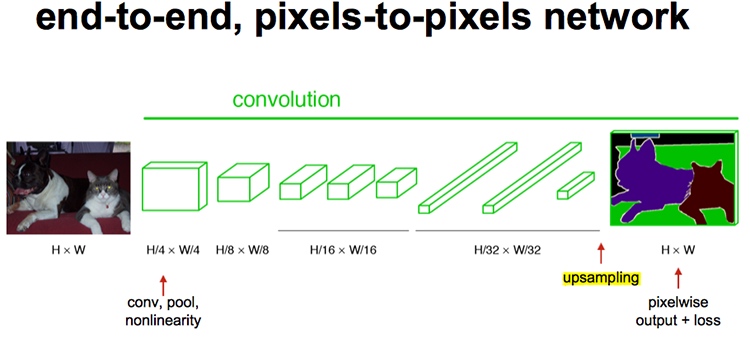
Upsampling
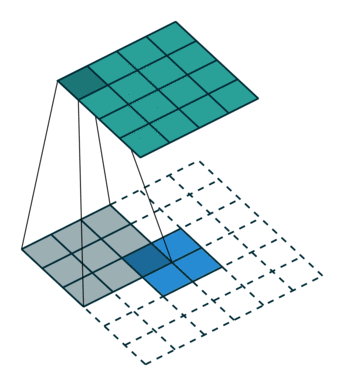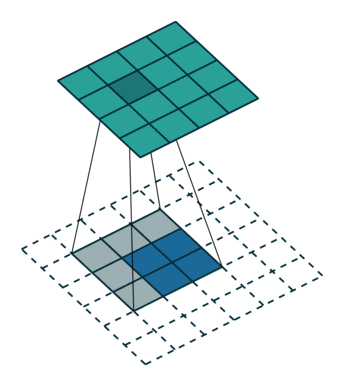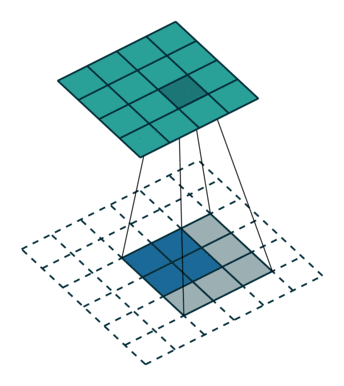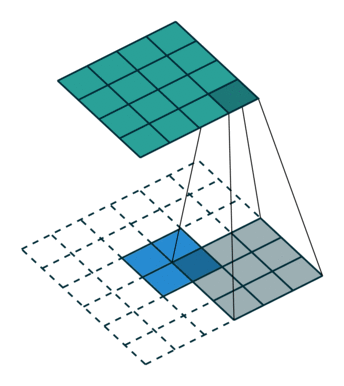
其實這篇paper內雖然叫做Deconvolution,但之前CS231n課程內的大神也有說到,叫做Transposed Convolution比較適合。
舉個例子來說:
4x4的圖片輸入,Filter Size為3x3, 沒有Padding / Stride, 則輸出為2x2。
輸入矩陣可展開為16維向量,記作x
輸出矩陣可展開為4維向量,記作y
Convolution運算可表示為y=Cx
C其實就是如下的稀疏陣,而Forwarding就改成了的矩陣運算
BackPropagation的話,假若已經從更深的網路得到了
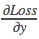
那麼就可以導出以下公式:
Deconvolution其實就是Forwarding時乘CT,而BackPropagation時乘(CT)T,即C。總結來說,Deconvolution等於Convolution在神經網絡結構的正向和反向傳播中的計算,做相反的計算。
Skip Architecture
由於縮小32倍結果超糟糕,所以FCN在前面的Pooling Layer進行Upsampling,然後結合這些結果來優化輸出。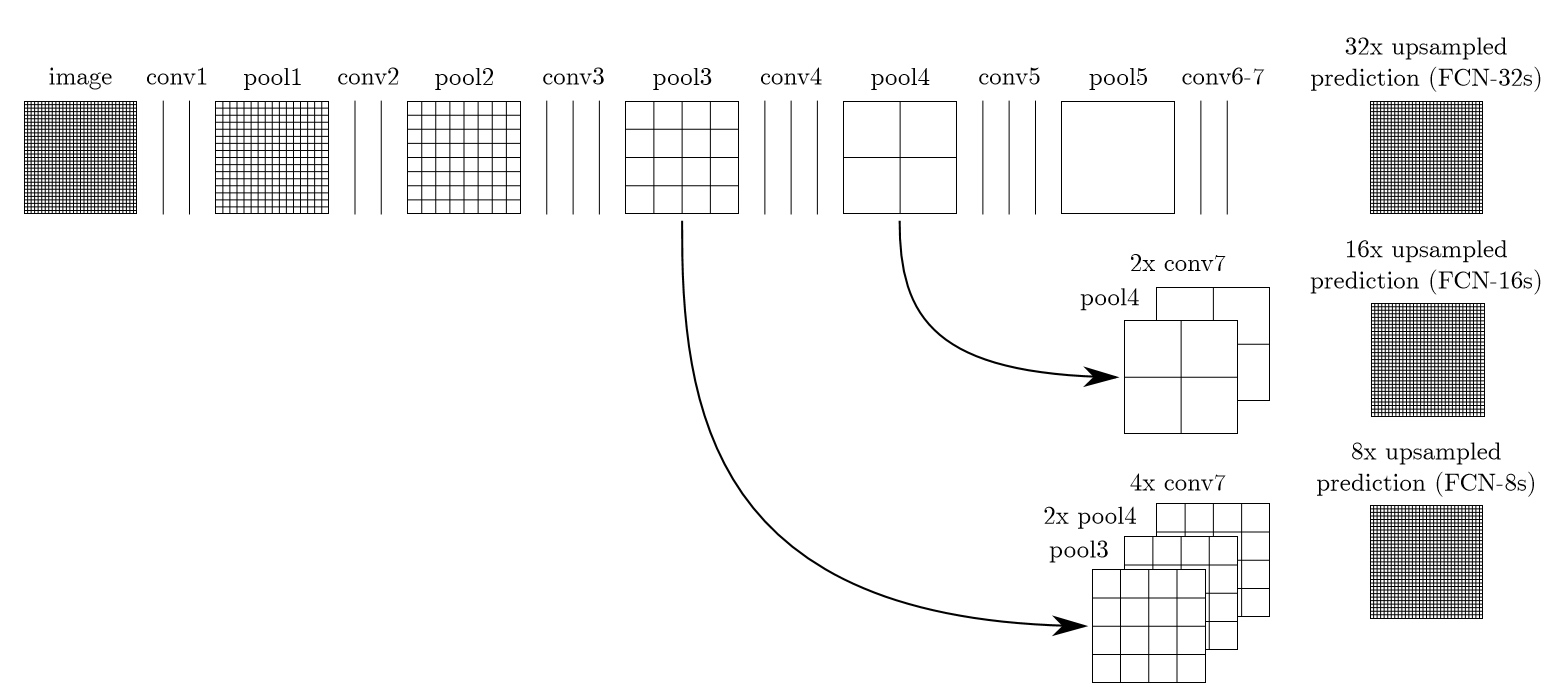
Architecture
總結一下前面速度分析的結果,一系列的優化方法:
- Downsampling Input:降低輸入解析度能都大幅度的加速,但同時會讓預測非常模糊
- Downsampling Feature:可以加速但同時會降低準確率
- Model Compression:壓縮訓練好的模型,通過減輕模型達到加速效果,可惜實驗效果不佳
針對以上的分析,發現,低解析度的圖片能夠有效降低運行時間,但是失去很多細節,而且邊界模糊;但是高解析度的計算時間難以忍受,ICNet總結了上述幾個問題,提出了一個綜合性的方法:使用低解析度加速捕捉語義,使用高解析度獲取細節,使用特徵融合(CFF)結合,同時使用guide label來監督,在限制的時間內獲得有效的結果。
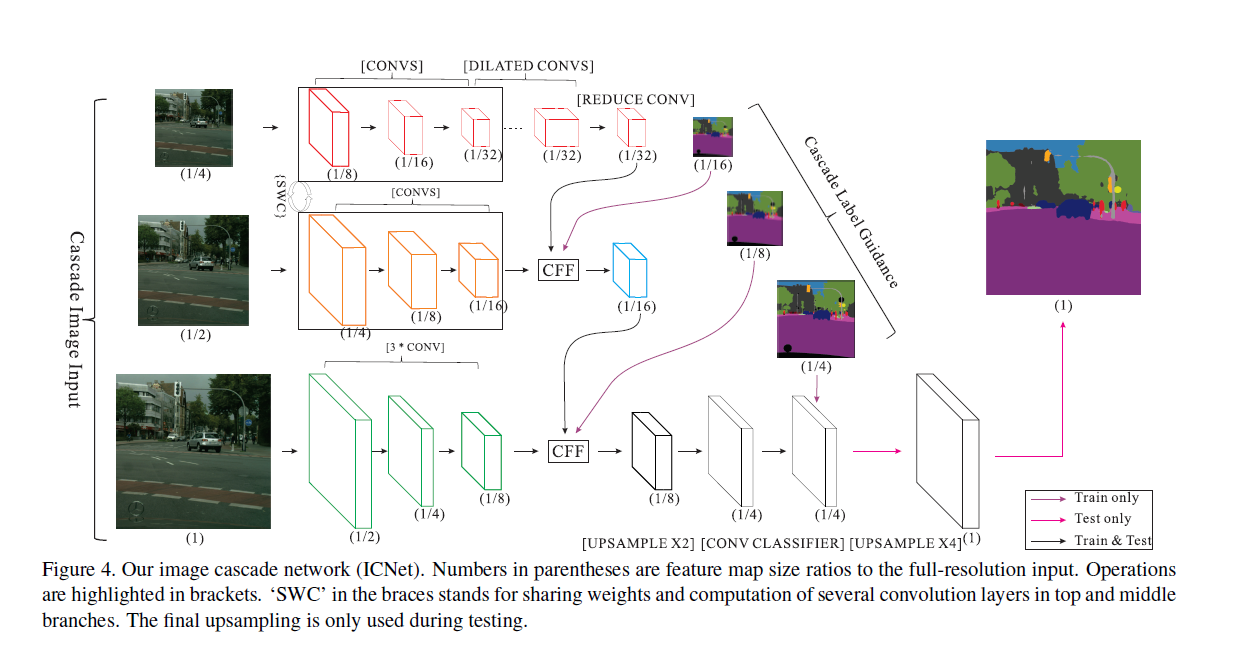
Branch Analysis
圖中用了原尺寸,1/2,1/4當input,低解析度分枝超過50層Convolution,來提取更多的語義信息(inference 18 ms),中解析度分枝有17層Convolution,但是由於權重共享,只有inference 6ms,而高解析度分枝是3 Convolution,有inference 9ms.
| 分枝 | 過程 | 耗時 |
|---|---|---|
| 低解析 | 低解析是FCN-based PSPNet的架構,總和有超過50層的Convolution,在中解析度的1/16輸出的基礎上,再縮放到1/32.經過Convolution後,然後使用幾個dilated convolution擴展接受野但不縮小尺寸,最終以原圖的1/32大小輸出feature map。 | 雖然層數較多,但是解析度低,速度快,且與分枝二共享一部分權重,耗時為18 ms |
| 中解析 | 以原圖的1/2的解析度作為輸入,經過17層Convolution後以1/8縮放,得到原圖的1/16大小feature map,再將低解析度分枝的輸出feature map通過CFF(cascade feature fusion )單元相融合得到最終輸出。值得注意的是:低解析度和中解析度的捲積參數是共享的。 | 有17個Convolution層,與分枝一共享一部分權重,與分枝一一起一共耗時6ms |
| 高解析 | 原圖輸入,經過三層的Convolution(Stride=2,Size=3x3)得到原圖的1/8大小的feature map,再將中解析度處理後的輸出通過CFF單元融合 | 有3個卷積層,雖然解析度高,因為少,耗時為9ms |
對於每個分枝的輸出特徵,首先會上採樣2倍做輸出,在訓練的時候,會以Ground truth的1/16、1/8/、1/4來指導各個分枝的訓練,這樣的輔助訓練使得梯度優化更為平滑,便於訓練收斂,隨著每個分枝學習能力的增強,預測沒有被任何一個分枝主導。利用這樣的漸變的特徵融合和級聯引導結構可以產生合理的預測結果。
ICNet使用低解析度完成語義分割,使用高解析度幫助細化結果。在結構上,產生的feature大大減少,同時仍然保持必要的細節。
Cascade Label Guidance
Branch Output
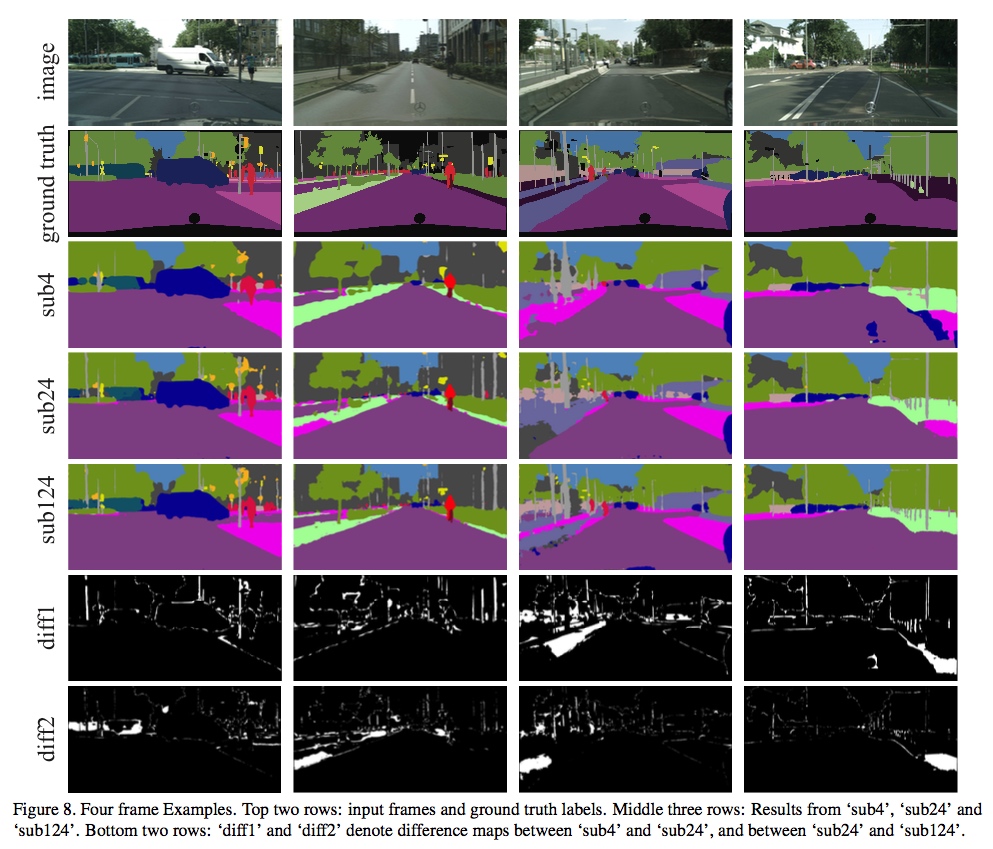
不同分枝的預測效果如下: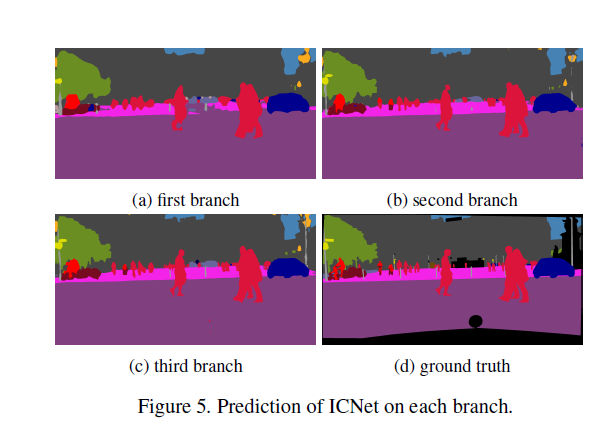
可以看到第三個分枝輸出效果無疑是最好的。在測試時,只保留第三分枝的結果。
Cascade Feature Fusion
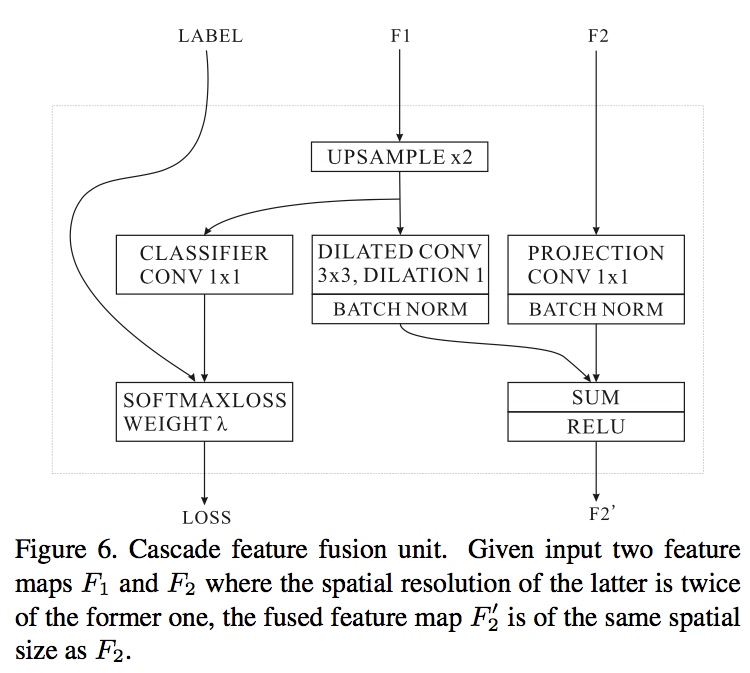
圖中的Loss是輔助Loss,F1是較低解析的分枝, F2是較高解析的分枝,
Loss Function
L=λ1L1+λ2L2+λ3L3
Loss是對應到每個downsampled score maps使用cross-entropy loss
依據CFF的設置,下分枝的lossL3的佔比λ3設置為1的話,則中分枝的lossL2的佔比λ2設置為0.4,上分枝的lossL1的佔比λ1設置為0.16
Experiment
| 項目 | 設置 |
|---|---|
| 平台 | Caffe,CUDA7.5 cudnnV5,TitanX一張 |
| 測量時間 | Caffe Time 100次取平均 |
| Batch Size | 16 |
| 學習速率 | Poly, Learning Rate 0.01, Momentum 0.9 |
| 迭代次數 | 30K |
| 權重衰減 | 0.0001 |
| 數據增強 | Random flip, 0.5 to 2 random scale |
| 資料集 | Cityscapes |
model Compression
以PSPNet50為例,直接壓縮結果如下表Baseline:
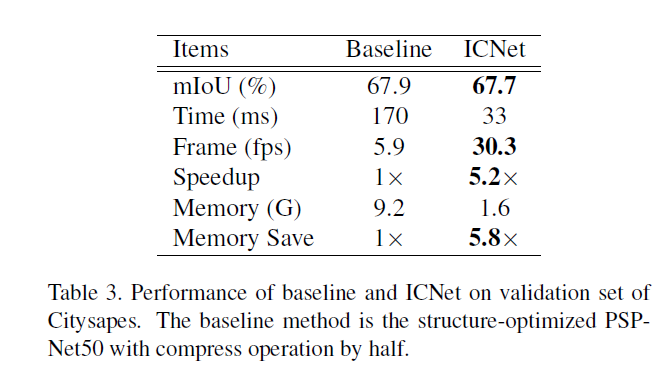
mIoU降低了,但時間170ms達不到realtime。這表明只有模型壓縮是達不到有良好分割結果的實時性能。對比ICNet,有類似的分割結果,但速度提升了5倍多。
Cascade Structure Experiment
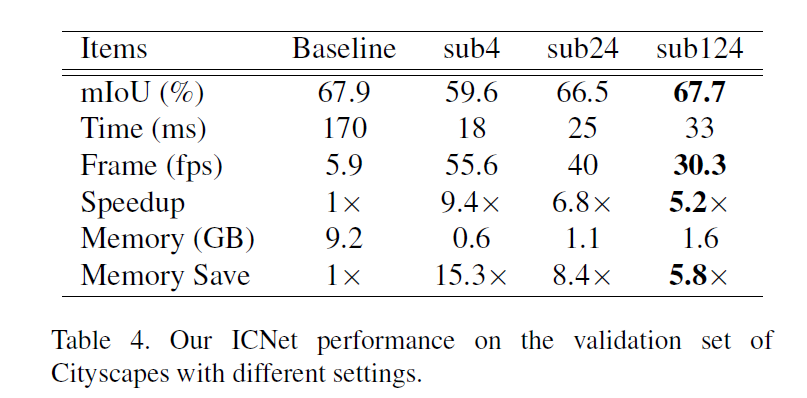
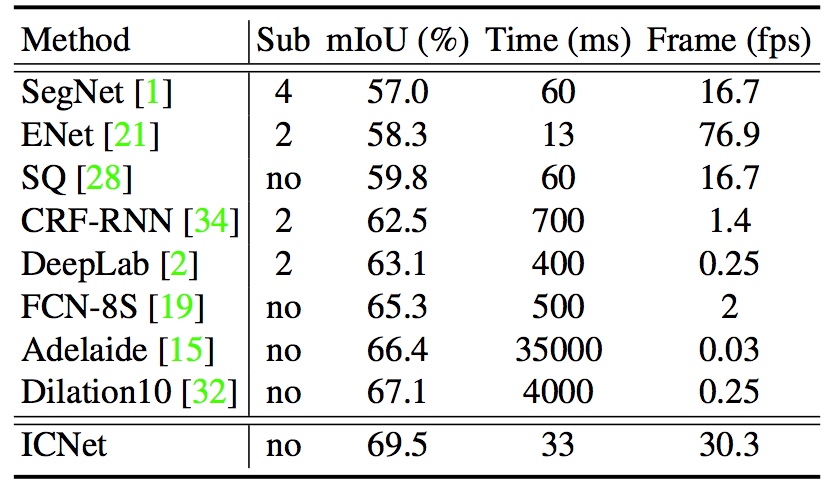
sub4代表只有低解析度輸入的結果,sub24代表前兩個分枝,sub124全部分枝。注意到全部分枝的速度很快,並且性能接近PSPNet了,且能保持30fps。而且Ram消耗也明顯減少了。
Visualization
Cityscape Comparison