Mask_RCNN V2.1版本
檔案:Model.py
Class MaskRCNN():
這部分是在程式碼主體所使用到RPN的部分, 其中傳入參數預設為此, for loop那邊可以看到有幾個從fpn的output就會有幾個rpn
RPN_ANCHOR_RATIOS = [0.5, 1, 2]
RPN_ANCHOR_STRIDE = 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| rpn_feature_maps = [P2, P3, P4, P5, P6] mrcnn_feature_maps = [P2, P3, P4, P5] if mode == "training": anchors = self.get_anchors(config.IMAGE_SHAPE) anchors = np.broadcast_to(anchors, (config.BATCH_SIZE,) + anchors.shape) anchors = KL.Lambda(lambda x: tf.Variable(anchors), name="anchors")(input_image) else: anchors = input_anchors rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE, len(config.RPN_ANCHOR_RATIOS), 256)
|
其中layer_output會長這樣, 就是一堆input是rpn_feature_maps = [P2, P3, P4, P5, P6] 輸出是[“rpn_class_logits”, “rpn_class”, “rpn_bbox”]的東西
1
| [[<tf.Tensor 'rpn_model/lambda_2/Reshape:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model/rpn_class_xxx/truediv:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model/lambda_3/Reshape:0' shape=(?, ?, 4) dtype=float32>], [<tf.Tensor 'rpn_model_1/lambda_2/Reshape:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_1/rpn_class_xxx/truediv:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_1/lambda_3/Reshape:0' shape=(?, ?, 4) dtype=float32>], [<tf.Tensor 'rpn_model_2/lambda_2/Reshape:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_2/rpn_class_xxx/truediv:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_2/lambda_3/Reshape:0' shape=(?, ?, 4) dtype=float32>], [<tf.Tensor 'rpn_model_3/lambda_2/Reshape:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_3/rpn_class_xxx/truediv:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_3/lambda_3/Reshape:0' shape=(?, ?, 4) dtype=float32>], [<tf.Tensor 'rpn_model_4/lambda_2/Reshape:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_4/rpn_class_xxx/truediv:0' shape=(?, ?, 2) dtype=float32>, <tf.Tensor 'rpn_model_4/lambda_3/Reshape:0' shape=(?, ?, 4) dtype=float32>]]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| layer_outputs = [] for p in rpn_feature_maps: layer_outputs.append(rpn([p])) output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"] outputs = list(zip(*layer_outputs)) outputs = [KL.Concatenate(axis=1, name=n)(list(o)) for o, n in zip(outputs, output_names)] rpn_class_logits, rpn_class, rpn_bbox = outputs
|
RPN_GRAPH
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be applied to anchors.
在上方的時候有執行了這行, 三個參數對應到anchor_stride, anchors_per_location, depth, 為啥要這樣包的原因是因為可以用同樣的weight好幾次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE, len(config.RPN_ANCHOR_RATIOS), 256) Input() is used to instantiate a Keras tensor. For instance, if a, b and c and Keras tensors, it becomes possible to do: model = Model(input=[a, b], output=c) def build_rpn_model(anchor_stride, anchors_per_location, depth): """ Builds a Keras model of the Region Proposal Network. It wraps the RPN graph so it can be used multiple times with shared weights. anchors_per_location: number of anchors per pixel in the feature map anchor_stride: Controls the density of anchors. Typically 1 (anchors for every pixel in the feature map), or 2 (every other pixel). depth: Depth of the backbone feature map. Returns a Keras Model object. The model outputs, when called, are: rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax) rpn_probs: [batch, W, W, 2] Anchor classifier probabilities. rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be applied to anchors. """ input_feature_map = KL.Input(shape=[None, None, depth], name="input_rpn_feature_map") outputs = rpn_graph(input_feature_map, anchors_per_location, anchor_stride) return KM.Model([input_feature_map], outputs, name="rpn_model")
|
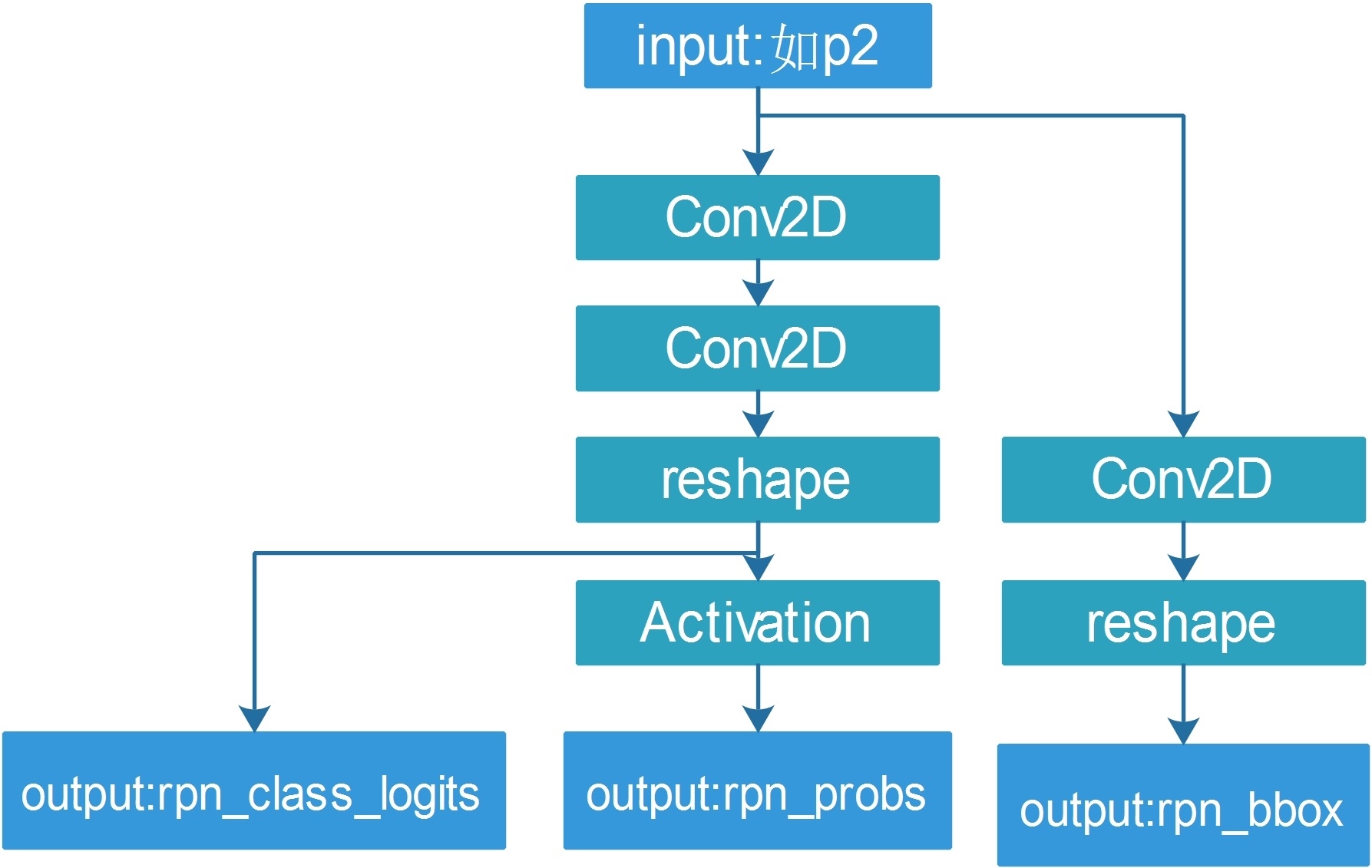
feature map->Conv(3x3,512)->RELU 後得到shared feature map
接下來就兵分兩路
這邊有點奇怪的是 下面這邊
理論上來說應該是要 len(RATIOS)*len(RPN_ANCHOR_SCALES) # 3 x 5
但實質上只有3而已
1 2 3
| RPN_ANCHOR_RATIOS = [0.5, 1, 2] RPN_ANCHOR_SCALES = (32, 64, 128, 256, 512) anchors_per_location = len(config.RPN_ANCHOR_RATIOS)
|
計算分數
shared feature map->Conv(1x1,2*3)->linear_activation
接著得到的東西會reshape成2xN的樣式的到rpn_class_logits, 接著才做softmax
# Reshape to [batch, anchors, 2]
rpn_class_logits = KL.Lambda(
lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x)
計算BBOX 偏移
shared feature map->Conv(1x1,4*3)->linear_activation
接著得到的東西會reshape成2xN的樣式的到rpn_class_logits
# Reshape to [batch, anchors, 4]
rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| def rpn_graph(feature_map, anchors_per_location, anchor_stride): """Builds the computation graph of Region Proposal Network. feature_map: backbone features [batch, height, width, depth] anchors_per_location: number of anchors per pixel in the feature map anchor_stride: Controls the density of anchors. Typically 1 (anchors for every pixel in the feature map), or 2 (every other pixel). Returns: rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax) rpn_probs: [batch, H, W, 2] Anchor classifier probabilities. rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be applied to anchors. """ shared = KL.Conv2D(512, (3, 3), padding='same', activation='relu', strides=anchor_stride, name='rpn_conv_shared')(feature_map) x = KL.Conv2D(2 * anchors_per_location, (1, 1), padding='valid', activation='linear', name='rpn_class_raw')(shared) rpn_class_logits = KL.Lambda( lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x) rpn_probs = KL.Activation( "softmax", name="rpn_class_xxx")(rpn_class_logits) x = KL.Conv2D(anchors_per_location * 4, (1, 1), padding="valid", activation='linear', name='rpn_bbox_pred')(shared) rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x) return [rpn_class_logits, rpn_probs, rpn_bbox]
|