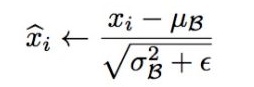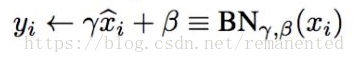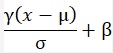from keras.engine import Layer, InputSpec
from keras import initializers
from keras import regularizers
from keras import constraints
from keras import backend as K
from keras.utils.generic_utils import get_custom_objects
class GroupNormalization(Layer):
"""Group normalization layer
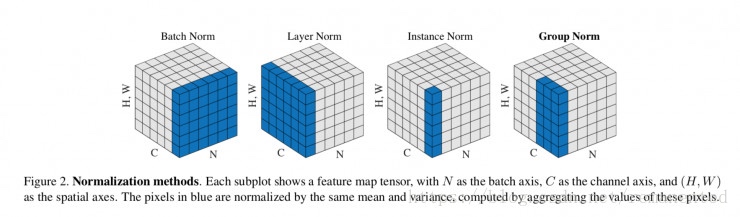
Group Normalization divides the channels into groups and computes within each group
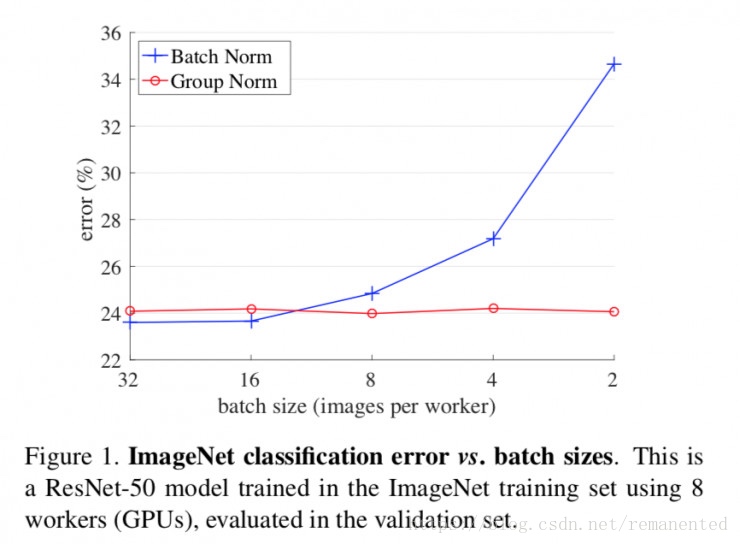
the mean and variance for normalization. GN's computation is independent of batch sizes,
and its accuracy is stable in a wide range of batch sizes
# Arguments
groups: Integer, the number of groups for Group Normalization.
axis: Integer, the axis that should be normalized
(typically the features axis).
For instance, after a `Conv2D` layer with
`data_format="channels_first"`,
set `axis=1` in `BatchNormalization`.
epsilon: Small float added to variance to avoid dividing by zero.
center: If True, add offset of `beta` to normalized tensor.
If False, `beta` is ignored.
scale: If True, multiply by `gamma`.
If False, `gamma` is not used.
When the next layer is linear (also e.g. `nn.relu`),
this can be disabled since the scaling
will be done by the next layer.
beta_initializer: Initializer for the beta weight.
gamma_initializer: Initializer for the gamma weight.
beta_regularizer: Optional regularizer for the beta weight.
gamma_regularizer: Optional regularizer for the gamma weight.
beta_constraint: Optional constraint for the beta weight.
gamma_constraint: Optional constraint for the gamma weight.
# Input shape
Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
# Output shape
Same shape as input.
# References
- [Group Normalization](https://arxiv.org/abs/1803.08494)
"""
def __init__(self,
groups=32,
axis=-1,
epsilon=1e-5,
center=True,
scale=True,
beta_initializer='zeros',
gamma_initializer='ones',
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
**kwargs):
super(GroupNormalization, self).__init__(**kwargs)
self.supports_masking = True
self.groups = groups
self.axis = axis
self.epsilon = epsilon
self.center = center
self.scale = scale
self.beta_initializer = initializers.get(beta_initializer)
self.gamma_initializer = initializers.get(gamma_initializer)
self.beta_regularizer = regularizers.get(beta_regularizer)
self.gamma_regularizer = regularizers.get(gamma_regularizer)
self.beta_constraint = constraints.get(beta_constraint)
self.gamma_constraint = constraints.get(gamma_constraint)
def build(self, input_shape):
dim = input_shape[self.axis]
if dim is None:
raise ValueError('Axis ' + str(self.axis) + ' of '
'input tensor should have a defined dimension '
'but the layer received an input with shape ' +
str(input_shape) + '.')
if dim < self.groups:
raise ValueError('Number of groups (' + str(self.groups) + ') cannot be '
'more than the number of channels (' +
str(dim) + ').')
if dim % self.groups != 0:
raise ValueError('Number of groups (' + str(self.groups) + ') must be a '
'multiple of the number of channels (' +
str(dim) + ').')
self.input_spec = InputSpec(ndim=len(input_shape),
axes={self.axis: dim})
shape = (dim,)
if self.scale:
self.gamma = self.add_weight(shape=shape,
name='gamma',
initializer=self.gamma_initializer,
regularizer=self.gamma_regularizer,
constraint=self.gamma_constraint)
else:
self.gamma = None
if self.center:
self.beta = self.add_weight(shape=shape,
name='beta',
initializer=self.beta_initializer,
regularizer=self.beta_regularizer,
constraint=self.beta_constraint)
else:
self.beta = None
self.built = True
def call(self, inputs, **kwargs):
input_shape = K.int_shape(inputs)
ndim = len(input_shape)
reduction_axes = list(range(len(input_shape)))
del reduction_axes[self.axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[self.axis] = input_shape[self.axis]
reshape_group_shape = list(input_shape)
reshape_group_shape[self.axis] = input_shape[self.axis] // self.groups
group_shape = [-1, self.groups]
group_shape.extend(reshape_group_shape[1:])
group_reduction_axes = list(range(len(group_shape)))
needs_broadcasting = (sorted(reduction_axes) != list(range(ndim))[:-1])
inputs = K.reshape(inputs, group_shape)
mean = K.mean(inputs, axis=group_reduction_axes[2:], keepdims=True)
variance = K.var(inputs, axis=group_reduction_axes[2:], keepdims=True)
inputs = (inputs - mean) / (K.sqrt(variance + self.epsilon))
original_shape = [-1] + list(input_shape[1:])
inputs = K.reshape(inputs, original_shape)
if needs_broadcasting:
outputs = inputs
if self.scale:
broadcast_gamma = K.reshape(self.gamma, broadcast_shape)
outputs = outputs * broadcast_gamma
if self.center:
broadcast_beta = K.reshape(self.beta, broadcast_shape)
outputs = outputs + broadcast_beta
else:
outputs = inputs
if self.scale:
outputs = outputs * self.gamma
if self.center:
outputs = outputs + self.beta
return outputs
def get_config(self):
config = {
'groups': self.groups,
'axis': self.axis,
'epsilon': self.epsilon,
'center': self.center,
'scale': self.scale,
'beta_initializer': initializers.serialize(self.beta_initializer),
'gamma_initializer': initializers.serialize(self.gamma_initializer),
'beta_regularizer': regularizers.serialize(self.beta_regularizer),
'gamma_regularizer': regularizers.serialize(self.gamma_regularizer),
'beta_constraint': constraints.serialize(self.beta_constraint),
'gamma_constraint': constraints.serialize(self.gamma_constraint)
}
base_config = super(GroupNormalization, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return input_shape